[알고리즘] 아호 코라식(Aho-Corasick) 알고리즘
1. 개요
다음과 같은 두 개의 문자열이 있습니다.
S = "abababdddd" (String의 약자를 따서 S라 표현)
W = "bab" (Word의 약자를 따서 W라 표현)
아시는거처럼 S에서 W가 존재하는지를 찾아내는, 이른바 일대일 문자열 패턴 매칭 알고리즘으로는 KMP 알고리즘이 있습니다.
그런데 매칭에 사용될 패턴이 다음과 같이 여러 개라면 어떨까요? 🤔
S = "abababdddd"
W = {"bab", "bd", "ab"}
즉, 하나의 문자열 안에서 여러 개의 부분 문자열이 존재하는지 찾아내는 일대다 문자열 패턴 매칭이라면 어떻게 할 수 있을까요?
물론 W 집합 안의 문자열에 대해 하나씩 KMP 알고리즘을 돌려보는 방법도 가능합니다.
KMP 알고리즘의 시간 복잡도는 $O(n+m)$ 니깐,
P 집합 안의 문자열의 갯수가 k개라고 할때 KMP 알고리즘으로 일대다 문자열 패턴 매칭을 했을 경우의 시간 복잡도는..
$O(kn+m_{1}+m_{2}+...+m_{k})$ 입니다.
2. 아호 코라식(Aho-Corasick) 알고리즘이란?
예상하신대로 아호 코라식은 일대다 문자열 패턴 매칭에 사용되는 알고리즘입니다. 패턴 문자열의 갯수와 상관없이 원본 문자열을 한 번만 훑어서 찾아내기 때문에 시간 복잡도는 $O(n+m_{1}+m_{2}+...+m_{k})$ 입니다. (KMP보다 놀라울정도로 빠른건 아닌거같은데... 🧐 )
어쨋든, 아호 코라식 알고리즘은 KMP 알고리즘의 확장이라고 볼 수 있습니다. (메커니즘이 비슷합니다).
KMP 알고리즘이 문자열과 문자열 간의 매칭이라면, 아호 코라식은 문자열과 트라이 간의 매칭입니다.
(아호 코라식을 배우시기 전에 KMP 알고리즘과 트라이 자료구조가 선행이 되어있어야 합니다..!)
다음과 같은 트라이가 있습니다. (S는 원본 문자열, W는 패턴 문자열 집합)

S 문자열과 트라이 간의 패턴 매칭 과정을 살펴보겠습니다.
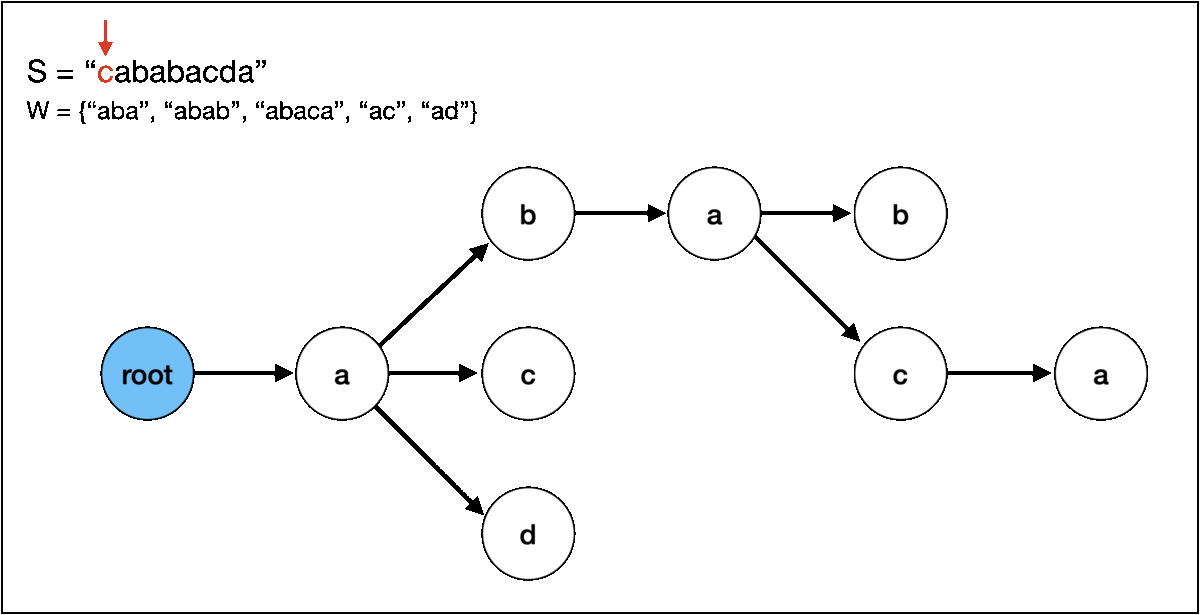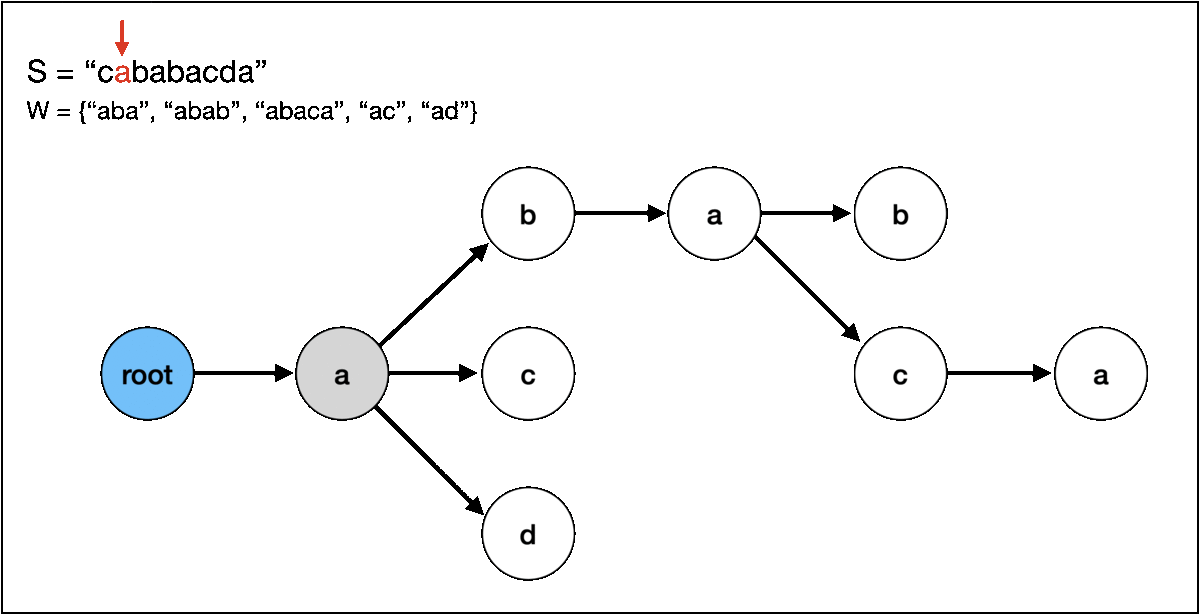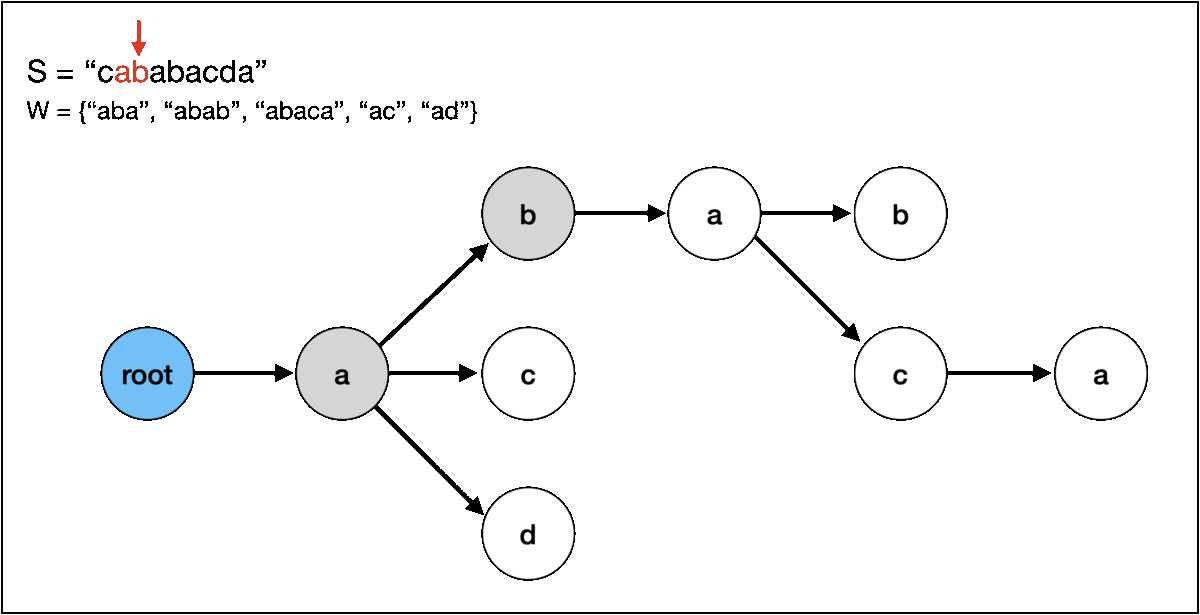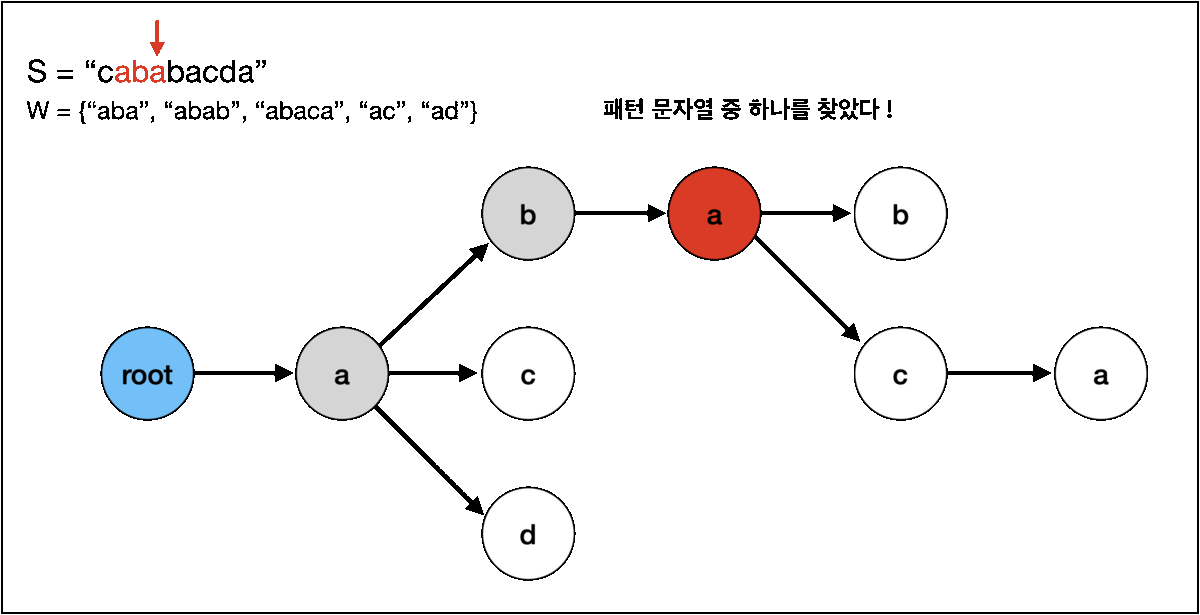
이어서 그 다음 문자인 b도 있기 때문에 똑같이 "abab" 라는 문자열을 찾을 수 있습니다. 문제는 그 다음인데요,
b 문자 다음은 a 문자인데 해당 문자는 없기 때문에 현재 노드를 가리키는 포인터가 롤백을 해야합니다.

트라이에서 매칭을 하다가 매칭이 실패했을 경우 현재 가리키고 있는 지점을 다른 곳으로 이동시키는 함수를 fail 함수라고 부릅니다.
그럼 포인터를 어디로 이동시켜야할까? 매칭에 실패한 문자 전까지의 일치한 문자열에 대해 접두사와 접미사가 같은 지점입니다.

다음부터는 지금까지의 과정을 반복하면 되니 생략하겠습니다. 😉
매칭의 과정과 실패했을 때 어디로 이동해야하는지는 알겠는데.. 어떻게 저 지점으로 이동할 수 있을까요?
이 부분부터 조금 어려울 수 있는데 하나씩 살펴보겠습니다.
트라이는 Trie 안에 각 노드를 가리킬 TrieNode 타입 변수를 두는 식으로 만들었습니다. (어떤 식으로 구현하는가는 자유입니다.)
class Trie {
TrieNode root = new TrieNode(true);
// 메서드는 생략..
}
class TrieNode {
TrieNode[] child;
TrieNode fail; // 실패했을 때, 이동해야할 지점을 가리킬 변수
boolean isEnd; // 완성된 문자열인지 표시 (일반적인 트라이에 나오는 개념입니다.)
boolean isRoot;
TrieNode(boolean isRoot) {
child = new TrieNode[26]; // 알파벳 소문자만 있다고 가정하고 사이즈는 26
this.isRoot = isRoot;
}
// 메서드는 생략...
}다음으로, 실패 함수 코드를 살펴보겠습니다. 해당 함수의 역할은 위 TrieNode의 fail 변수의 값을 채워주는 것입니다.
그러기 위해선 트라이를 탐색해야하기 때문에 BFS 탐색이 사용됩니다.
// 실패 함수 (KMP로 비교를 하다가 실패했을 때의 이동해야할 지점을 정의한다.)
// 일반적인 KMP 구현에서 getPi() 메서드에 해당한다.
void failure() {
Queue<TrieNode> q = new LinkedList<>();
trie.root.fail = trie.root; // root 회귀
q.add(trie.root);
// 트리에 담긴 문자열에 대해 접두사-접미사가 동일한 것을 뽑아내야 한다. (BFS 이용)
while (!q.isEmpty()) {
TrieNode currentNode = q.poll();
// 알파벳 소문자만 있다고 가정하고 크기는 26
for (int i = 0; i < 26; i++) {
TrieNode nextNode = currentNode.child[i];
if (nextNode == null) continue;
if (currentNode.isRoot) { // root 자식 노드의 fail은 그들의 부모인 root 노드가 된다.
nextNode.fail = trie.root;
} else {
TrieNode failure = currentNode.fail;
while (!failure.isRoot && failure.child[i] == null) {
failure = failure.fail;
}
if (failure.child[i] != null) {
failure = failure.child[i];
}
nextNode.fail = failure;
}
if (nextNode.fail.isEnd) {
nextNode.isEnd = true;
}
q.add(nextNode);
}
}
}세팅이 끝났으면 마지막으로 문자열과 트라이 간의 KMP 알고리즘을 사용하는 코드는 다음과 같습니다.
boolean kmp(String origin, TrieNode root) {
TrieNode currentNode = root;
boolean isFind = false;
for (int i = 0; i < origin.length(); i++) {
int idx = origin.charAt(i) - 'a';
while (!currentNode.isRoot && currentNode.child[idx] == null) {
currentNode = currentNode.fail;
}
if (currentNode.child[idx] != null) {
currentNode = currentNode.child[idx];
}
if (currentNode.isEnd) { // 원본 문자열에서 패턴 문자열 하나를 찾았다면
isFind = true;
}
}
return isFind;
}3. 참고자료
[1] m.blog.naver.com/PostView.nhn
[2] www.slideshare.net/ssuser81b91b/ahocorasick-algorithm
[3] koosaga.com/157
'Algorithm > Theory' 카테고리의 다른 글
| [자료구조] Trie(트라이) (0) | 2021.09.03 |
|---|---|
| [알고리즘] KMP(Knuth-Morris-Pratt) 알고리즘 (0) | 2021.03.10 |
| [알고리즘] 세그먼트 트리 (SegmentTree) (0) | 2021.03.05 |
| [알고리즘] LIS(Longest Increasing Subsequence) (0) | 2021.03.03 |
| [알고리즘] 슬라이딩 윈도우(Sliding Window) 알고리즘 (0) | 2020.10.31 |